What is a RAG (Retrieval-Augmented Generation) System?

Written by: Soumen das
Published on: Jun 26, 2024
Full form of RAG is Retrieval-Augmented Generation. This is a system that empowers Large Language Models (LLMs) by providing a relevant knowledge base to obtain accurate and contextually appropriate answers. While LLMs, such as GPT-3 and GPT-4, are capable of generating coherent and contextually relevant text based on vast amounts of pre-trained data, they sometimes struggle with accuracy and up-to-date information. RAG systems enhance the capabilities of LLMs by incorporating an additional retrieval step, which involves searching a large corpus of documents to find relevant information. This information is then fed into the generation process, ensuring that the output is not only fluent and contextually appropriate but also factually accurate and relevant to the latest available data. This combination of retrieval and generation allows RAG systems to provide more reliable and enriched responses, making them invaluable in applications requiring high accuracy and current information.
Understanding RAG Systems
A Retrieval-Augmented Generation (RAG) system is a type of AI that integrates two core technologies:
- Information Retrieval (IR): This involves searching and retrieving relevant documents or data from a large corpus.
- Text Generation (TG): This involves generating coherent and contextually appropriate text based on the retrieved information.
Diagram: RAG System Architecture
1. Retrieval Module:
- Function: Searches for and retrieves relevant documents or pieces of information from a pre-defined corpus.
- Tools: Often utilizes vector-based search techniques, such as BM25 or dense embeddings generated by transformer models.
2. Generation Module:
- Function: Generates text based on the information retrieved by the retrieval module.
- Tools: Uses advanced NLP models like GPT-4 to produce human-like responses.
3. Fusion Mechanism:
- Function: Integrates the retrieved information with the generated text to produce a final, coherent response.
- Tools: Combines probabilistic approaches and attention mechanisms to weigh the relevance of retrieved information.
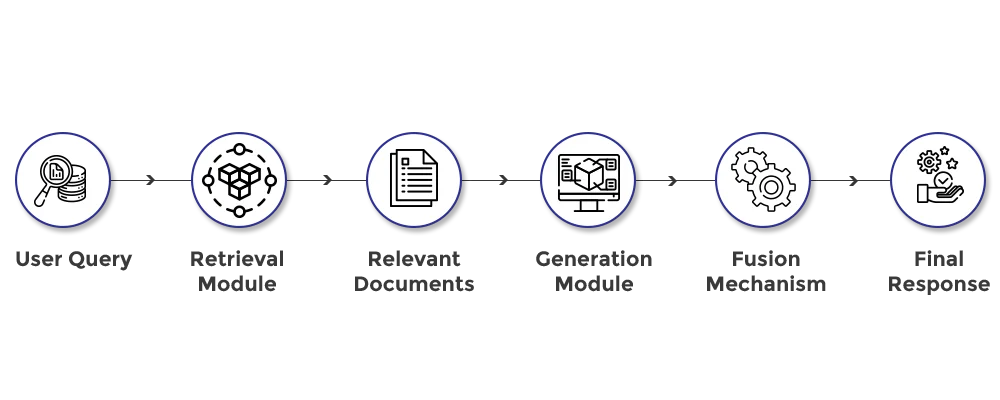
How RAG Works: A Step-by-Step Process
- Query Input: The user inputs a query or question.
- Retrieval Process: The retrieval module searches the corpus and fetches relevant documents or data related to the query.
- Document Selection: The most relevant pieces of information are selected based on relevance scores.
- Text Generation: The generation module takes the retrieved information and generates a response.
- Response Fusion: The generated response is refined by integrating the retrieved information to ensure accuracy and relevance.
- Final Output: The system outputs a coherent and contextually accurate response to the user.
Diagram: RAG System Architecture
Below is a simplified diagram illustrating the architecture of a RAG system:
Infographics: Key Features of RAG Systems
- Enhanced Accuracy: By retrieving relevant documents, RAG systems ensure that the generated responses are accurate and based on factual information.
- Context Awareness: RAG systems maintain context by integrating relevant information into the generated text.
- Versatility: Applicable in various domains such as customer support, research, and content creation.
- Efficiency: Reduces the time and effort required to generate relevant responses by leveraging pre-existing information.
Applications of RAG Systems
- Customer Support: Provides accurate and contextually relevant responses to customer queries by retrieving information from support databases.
- Research Assistance: Assists researchers by retrieving relevant literature and generating summaries or insights based on the information.
- Content Creation: Helps content creators by providing factually accurate and contextually relevant information to support their writing.
Advantages of RAG Systems
- Improved Response Quality: Combining retrieval with generation ensures that responses are both relevant and well-formed.
- Scalability: Capable of handling vast amounts of data, making it suitable for large-scale applications.
- Flexibility: Can be adapted for various use cases and integrated with different types of databases and information sources.
Challenges and Future Directions
- Computational Complexity: Managing and processing large amounts of data efficiently remains a challenge.
- Data Quality: The accuracy of the generated responses depends on the quality of the data in the corpus.
- Integration: Seamless integration of retrieval and generation modules requires sophisticated fusion mechanisms.


