Key Differences between R-CNN and CNN in Object Detection
Published Sep 02, 2024
Understanding R-CNN and Its Differences from CNN
Convolutional Neural Networks (CNNs) have revolutionized the field of computer vision with their ability to automatically learn and extract features from images. While CNNs are highly effective for image classification tasks, they fall short when it comes to object detection. This is where Region-based Convolutional Neural Networks (R-CNNs) come into play, providing a more sophisticated approach to detecting objects within images.
What is R-CNN?
R-CNN, which stands for Region-based Convolutional Neural Network, is a deep learning model designed specifically for object detection. Introduced by Ross Girshick et al. in 2014, R-CNNs aim to locate and classify multiple objects within an image, addressing the limitations of traditional CNNs.
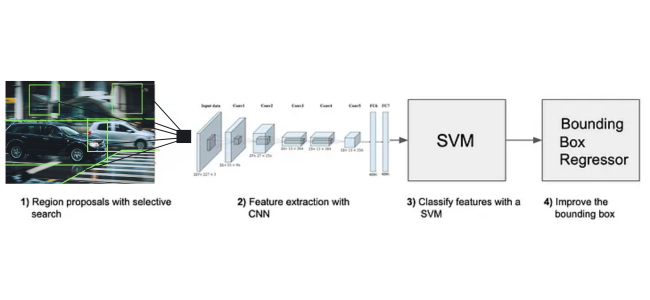
The R-CNN model operates in three main stages:
- Region Proposal: The algorithm first generates a set of region proposals or candidate bounding boxes that might contain objects. Selective Search is commonly used for this purpose.
- Feature Extraction: Each region proposal is then cropped and resized to a fixed size. A CNN is used to extract a feature vector from each region.
- Classification and Bounding Box Regression: The extracted features are fed into a classifier (typically an SVM) to determine the object class. Additionally, a bounding box regressor refines the coordinates of the proposed regions to improve localization accuracy.
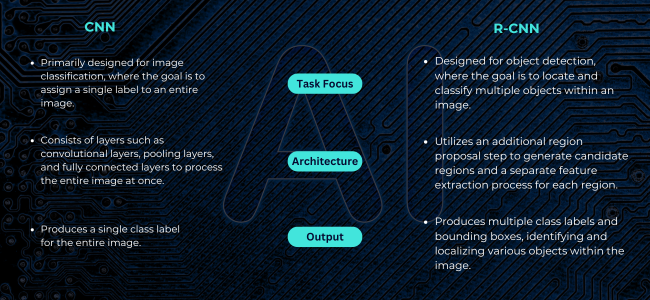
Differences Between CNN and R-CNN
While both CNNs and R-CNNs are used in the field of computer vision, they serve different purposes and have distinct architectures:
- Task Focus:
- CNN: Primarily designed for image classification, where the goal is to assign a single label to an entire image.
- R-CNN: Designed for object detection, where the goal is to locate and classify multiple objects within an image.
- Architecture:
- CNN: Consists of layers such as convolutional layers, pooling layers, and fully connected layers to process the entire image at once.
- R-CNN: Utilizes an additional region proposal step to generate candidate regions and a separate feature extraction process for each region.
- Output:
- CNN: Produces a single class label for the entire image.
- R-CNN: Produces multiple class labels and bounding boxes, identifying and localizing various objects within the image.
Libraries and Resources for Training R-CNN Models
Several libraries and frameworks facilitate the development and training of R-CNN models:
- TensorFlow: Provides extensive support for building and training R-CNN models. The TensorFlow Object Detection API includes implementations of Faster R-CNN and Mask R-CNN.
- PyTorch: Offers versatile tools for constructing and training R-CNN models. The torchvision library contains pre-trained models and utilities for object detection.
- Detectron2: A high-performance object detection library developed by Facebook AI Research. It includes implementations of Faster R-CNN, Mask R-CNN, and other state-of-the-art models.
Example: Training an R-CNN Model Using PyTorch
Here’s a simplified example of how to train a Faster R-CNN model using PyTorch and torchvision:
import torch
import torchvision
from torchvision.models.detection import fasterrcnn_resnet50_fpn
from torchvision.transforms import functional as F
from torch.utils.data import DataLoader, Dataset
# Define a custom dataset
class CustomDataset(Dataset):
def __init__(self, image_paths, annotations, transforms=None):
self.image_paths = image_paths
self.annotations = annotations
self.transforms = transforms
def __getitem__(self, idx):
img_path = self.image_paths[idx]
img = Image.open(img_path).convert("RGB")
target = self.annotations[idx]
if self.transforms:
img = self.transforms(img)
return img, target
def __len__(self):
return len(self.image_paths)
# Load the dataset
train_dataset = CustomDataset(image_paths, annotations, transforms=F.to_tensor)
train_loader = DataLoader(train_dataset, batch_size=2, shuffle=True, num_workers=4)
# Load a pre-trained Faster R-CNN model
model = fasterrcnn_resnet50_fpn(pretrained=True)
# Replace the classifier with a new one for our specific number of classes
num_classes = 2 # 1 class (object) + background
in_features = model.roi_heads.box_predictor.cls_score.in_features
model.roi_heads.box_predictor = torchvision.models.detection.faster_rcnn.FastRCNNPredictor(in_features, num_classes)
# Training loop
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model.to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.005, momentum=0.9, weight_decay=0.0005)
num_epochs = 10
for epoch in range(num_epochs):
model.train()
for images, targets in train_loader:
images = [img.to(device) for img in images]
targets = [{k: v.to(device) for k, v in t.items()} for t in targets]
optimizer.zero_grad()
loss_dict = model(images, targets)
losses = sum(loss for loss in loss_dict.values())
losses.backward()
optimizer.step()
print(f"Epoch: {epoch}, Loss: {losses.item()}")
print("Training complete.")
R-CNN and its derivatives have significantly advanced the field of object detection, providing robust solutions for identifying and localizing objects within images. While CNNs excel at image classification, R-CNN models address the more complex task of object detection, enabling a wide range of applications from autonomous driving to medical imaging. With powerful frameworks like TensorFlow, PyTorch, and Detectron2, developing and training R-CNN models has become more accessible, driving further innovation and application of these technologies.


